











시간이 남아 지난 학기에 했던 데이터 마이닝 프로젝트를 올려본다. PPT의 경우 2시간만에 만들어서 올리기도 부끄럽다.
프로젝트의 주제는, 갤럭시2의 센서를 통해 입력된 561가지 변수를 토대로 6가지 움직임을 예측해 보는 것이다.
6가지 움직임은 다음과 같다
1 WALKING
2 WALKING_UPSTAIRS
3 WALKING_DOWNSTAIRS
4 SITTING
5 STANDING
6 LAYING
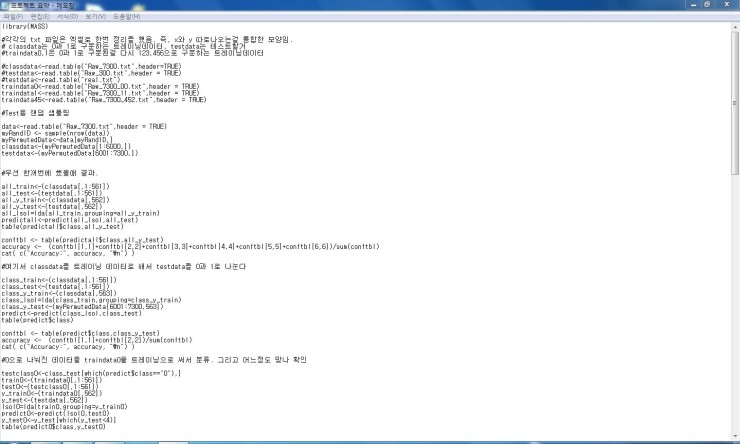
데이터 크기가 커 엑셀이나 엑셀 마이너로는 당연히 무리가 있어 R을 통해 데이터를 분석하고 데이터 마이닝을 해보았다.
일단 트레이닝 데이터 7300개를 받아 이를 통해 모델링을 해놓고 실전 데이터 1000개에 대해 예측해보고 예측력을 판단하는 것이었다.
R을 이용하여도 Raw 데이터에서부터의 예측에는 총 1분 정도가 소요될 정도로 무거운 계산이였다.
그럼에도, 굉장히 복잡한 계산인데 빠른 속도로 수행됨에 따라 다시 한번 컴퓨터의 기능에 놀라지 않을 수 없었다.
(즉, KNN의 경우 변수 하나하나와 다른 변수 하나하나의 거리를 분석하여 가까운것끼리를 같은거라 보는 분석방법인데 일반적 거리계산인
2차원이 아닌 561차원이므로 계산시간이 어마어마하다. 7000개의 점과 561차원의 계산이라 불가능할줄 알았는데 의외로 해내긴 한다.)
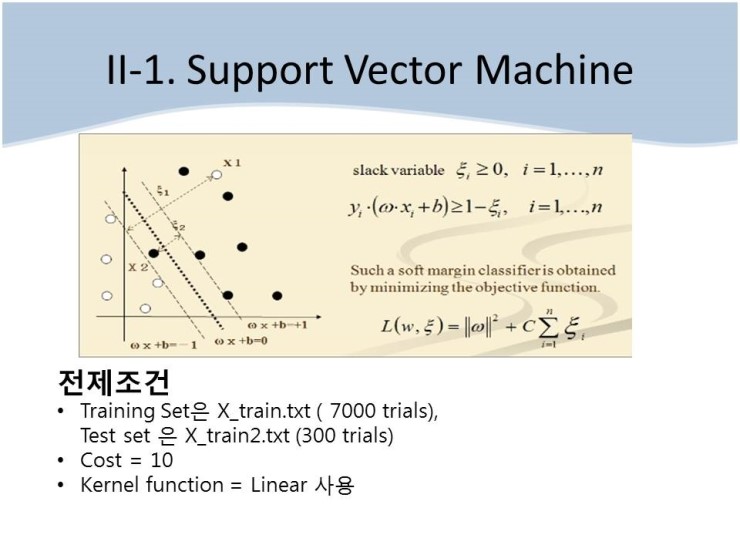
여기서 수행한 방법은 총 3가지, Support Vector machine, discriminant analysis, KNN 이였다.
그 이유는 연속형 데이터를 Input 으로 받아 카테고리형 데이터를 Output으로 내기 때문인데, 예를들어 NaiiveBayes 의 경우 카테고리형
데이터를 받기 때문에 여기에는 적용할 수 없다. Regression의 경우에도 연속형 데이터를 Output으로 내기 때문에 안되고
Logistic Regression의 경우에는 카테고리형 데이터를 Output으로 내기때문에 가능하나, 예측력이 낮아서 버렸던걸로 기억한다.
사실 3,4개월 전에 했던 과제인데다 이후 복습한번 해본 적이 없으므로 잘 기억이 안난다...
어쨌든, 결과적으로는 위 3가지 방법을 사용하여 수행하였다. 이를 한가지 한가지 보면
Support Vector machine 란... 사실 그 계산과정이나 이론이 복잡해서 제대로 듣지도 못했고 이해도 못했다.
대략적으로는 위에서 굵은 선, 구분하는 선을 계산해내는 방법론적인 것이라고 기억하는데, 어차피 우리는 툴로서 사용하기에
그냥 R에서 함수로 써먹어서 이해는 딱히 하지 않았다.(산업공학과는 저런 어려운 수학을 배우지 않는다. 통계 말고는 수학이 아냐...)
위의 경우에는 구분하기 쉽게 모양지어있지만, 그렇지 않아도 다양한 방식으로 구분이 된다고 한다.
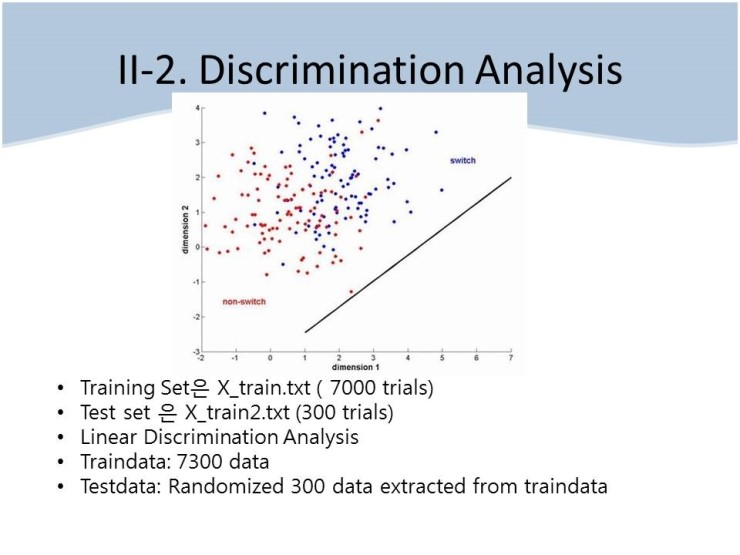
다음으로, 쉬운 적용에도 불구하고 놀라운 예측력을 보여준 discriminant analysis .
이는 목표 Y가 정해져 있을때 (여기서는 1,2,3,4,5,6이 정해져 있으므로 Supervised learning이라 할 수 있다) 단순히 각각에 대해
거리만을 계산하여 classification을 하는 게 아니라 평균과 표준편차를 고려하는 방법이다.
용어로 말하자면 Euclidean Distance 이 아니라 Statistical (Mahalanobis) Distance 을 고려하여 classification을 해낸다.
R을 이용할때, SVM에 비해 몹시 쉬운편이었던걸로 기억한다.
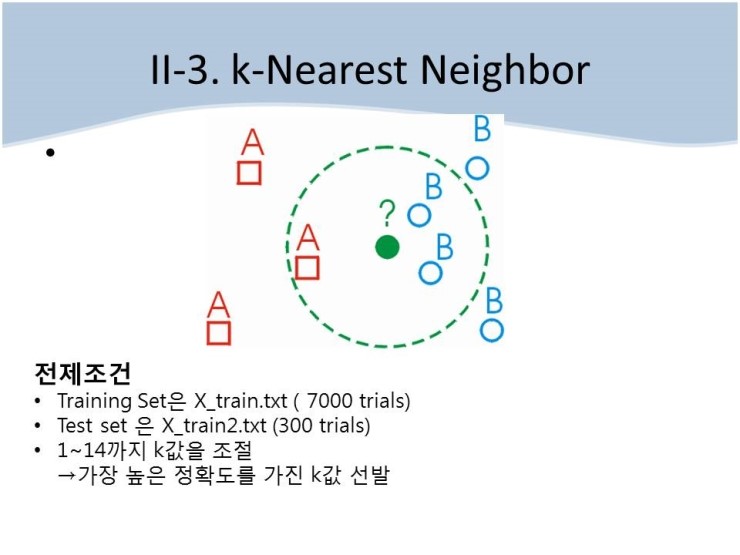
KNN은 모델링이 필요 없다고 볼 수 있는데, 이유는 단순히 각각의 점에 대해 다른 모든 점의 거리만을 계산하고, 가까운 k개의 점에 대해
더 많은 종류의 것에다가 자신을 맞추어두는 방식이기 때문이다. 다시말하면, y가 1,2만이 있다고 하고 100개의 점이 있다고 해보자. 그 때
미상의 점 x가 들어오면 다른 100개의 점과의 거리를 계산하고 가까운 순서로 k개의 점에 대해 1이 많은지 2가 많은지 보고 많은쪽이
맞다고 보는 방식이다.
각각에 대한예측력은 위 PPT에 써놨다고 믿고... 어쨌든, 위 프로젝트는 수행과정에서 조금의 '조작'이 있어서 PPT는 저렇게 써놨지만
결과적으로 Discrimination analysis 만을 썼을때가 가장 예측력이 좋았고, 그다음이 SVM , 그다음이 KNN이었다.
그리고 이에 있어 123456을 동적동작 0과 정적동작 1로 맞추어 놓고 이를 우선 classification한 뒤에 다시 0과 1을 대상으로
classification를 해낸다. 각각의 트레이닝 데이터는 0에 대한 트레이닝데이터, 1에 대한 트레이닝데이터로 나눠서 두었다.
이렇게 했을때 약 95%의 예측력을 보이며
SVM을 통해 할 때는 Classification이 아니라 Clustering을 해낸 후에 SVM을 했던 것 같다. 각각을 조에서 역할을 나눠 수행해
확실하게 기억은 안 난다. Classification과 Clustering의 차이는, Supervised냐, Unsupervised냐의 차이인데 Y가 정해져 있느냐와
정해져 있지 않느냐의 차이이다. 즉, 네이버에서 검색어만으로 사용자를 분류할때 '남자' 와 '여자' 라는 Y를 정한 상태로 분류하면
Classification, 그냥 무턱대로 2개로 분류하게 하면 Clustering 이다.
SVM으로 했을 때는 94%정도의 예측력을 보였다. 뭐 비슷한 수준이었던 듯. KNN은 시간도 오래걸려서 그냥 말았다.
'Data Mining & R' 카테고리의 다른 글
| K-means (0) | 2016.04.24 |
|---|---|
| [JAVA] Weka 라이브러리를 활용하여 KNN 사용하기 (1) | 2016.04.20 |
| k Nearest Neighbors(KNN) (0) | 2016.04.20 |
| Deep Neural Network (DNN) (0) | 2016.04.19 |
| Classification - Decision Tree 예시 (0) | 2016.04.17 |