사이킷-런(Scikit-learn)
파이썬(Python)은 수학, 과학, 통계에 없어서는 안 될 프로그래밍 언어로 자리 잡았다. 다양한 애플리케이션에서 사용할 수 있는 폭넓은 라이브러리를 갖추고 있을 뿐만 아니라, 손쉽게 도입할 수 있기 때문이다. 사이킷-런(Scikit-learn)은 수학과 과학 분야에서 넘피(NumPy), 사이피(SciPy), matplotlib 등을 폭넓게 이용한다. 결과물인 라이브러리는 인터랙티브 '워크벤치' 애플리케이션에 이용하거나, 다른 소프트웨어에 탑재시켜 재사용할 수 있다. BSD 라이선스로 제공되는 오픈소스로 재사용이 가능하다.
프로젝트 : 사이킷-런
깃허브 : https://github.com/scikit-learn/scikit-learn
Read more: http://www.itworld.co.kr/slideshow/90912?slide=1#stage_slide#csidxb865d777acec2279c187217fb41f5b4 
Copyright © LinkBack
쇼군(Shogun)
가장 오래된 기계 학습 라이브러리들 가운데 하나인 쇼군(Shogun)은 1999년 개발됐으며, C++에 기반을 두고 있지만, 여기에만 국한되지 않는다. 쇼군은 SWIG 라이브러리 덕분에 자바, 파이썬, C#, 루비, R Lua, Octave, Matlab에서도 이용할 수 있다.
쇼군에 비견할 수 있는 라이브러리로는 Mlpack이 있는데, C++ 기반으로 2011년 개발됐다. 그러나 Mlpack보다 더 많은 통합 API를 제공하는 쇼군이 쉽고 빠르게 다룰 수 있다는 평가를 받고 있다.
Project: Shogun
GitHub: https://github.com/shogun-toolbox/shogun
Read more: http://www.itworld.co.kr/slideshow/90912?slide=2#stage_slide#csidx06726fe5b1e968fb20b4b4e7d2989f7 
Copyright © LinkBack

어코드(Accord) Framework/AForge.net
닷넷(.Net)용 단일 프로세싱 프레임워크 겸 기계 학습 라이브러리인 어코드(Accord)는 AForge.net의 확장판이다. 여기에서 '단일 프로세싱’은 이미지를 통합하거나 얼굴을 인식하는 등 이미지와 음성을 처리하는 여러 기계 학습 알고리즘을 일컫는다. 여기에는 동영상 등 이미지 스트림을 대상으로 하는 비전 프로세싱(vision processing) 알고리즘이 포함되며, 움직이는 물체를 추적하는 기능을 구현하는 데 사용되기도 한다. 어코드에는 신경망에서 의사결정 나무 시스템에 이르기까지 보다 전통적인 기계 학습 기능을 구현하는 라이브러리가 포함되어 있다.
Project: Accord Framework/AForge.net
GitHub: https://github.com/accord-net/framework/
Read more: http://www.itworld.co.kr/slideshow/90912?slide=3#stage_slide#csidxfe534916017815a8da34467d8dab60f 
Copyright © LinkBack
Mahout
Mahout 프레임워크는 오랜 기간 하둡과 연관됐으나, 상당수는 하둡 이외에서도 작동된다. 해당 프레임워크는 하둡이나 자체적인 독립형 애플리케이션으로 분리될 수 있는 하둡 프로젝트와 통합할 독립형 애플리케이션에 유용하다.
그러나 단점도 있다. 하둡용인 고성능의 스파크 프레임워크를 지원하지 않는 대신, 노후화가 진행되고 있는 맵리듀스 프레임워크를 지원한다. 더 이상은 맵리듀스 기반 알고리즘을 수용하지는 않지만, 더 높은 성능의 미래형 라이브러리를 추구한다면 MLib이 나은 선택이 될 수 있다.
Project: Mahout
Read more: http://www.itworld.co.kr/slideshow/90912?slide=4#stage_slide#csidxd8b5420aad281778187e663dd396aea 
Copyright © LinkBack
MLlib
아피치의 스파크 및 하둡용 기계 학습 라이브러리인 MLlib은 속도와 확정이 뛰어난 알고리즘과 유용한 데이터 형식을 지원한다. 하둡 프로젝트이기 때문에 MLib의 주 언어는 자바다. 그러나 파이썬 또한 넘피 라이브러리를 이용해서 MLib을 연결할 수 있으며, 스칼라(Scala) 사용자들도 MLib에 코드를 쓸 수 있다. 하둡 클러스터가 실용적이지 못하다면, 하둡 없이 스파크에 배치할 수 있다. EC2와 Mesos도 마찬가지이다.
또 다른 프로젝트인 MLbase는 MLib에 기반을 두고 있는데, 결과 도출은 좀 더 쉬운 프로젝트다. 코드를 쓰는 대신 SQL을 이용해 쿼리를 처리할 수 있기 때문이다.
Project: MLlib
Read more: http://www.itworld.co.kr/slideshow/90912?slide=5#stage_slide#csidx15ad5800635fae4b2ce3b4955951964 
Copyright © LinkBack
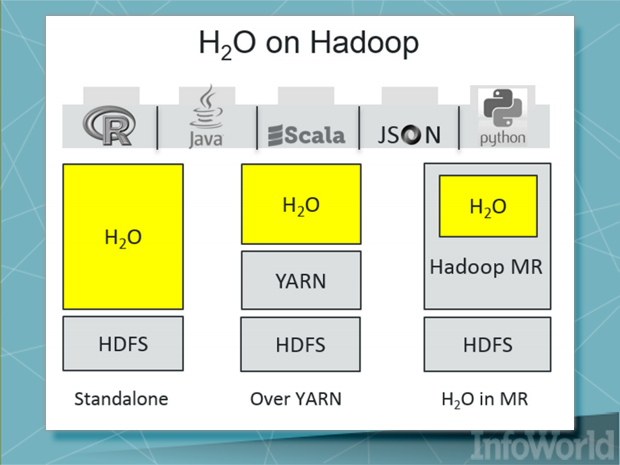
H2O
옥스데이터(Oxdata)의 H2O는 이미지 분석보다는 부정행위나 트렌드 분석 등 비즈니스 프로세스에 더 적합한 알고리즘이다. H2O는 HDFX에는 스탠드얼론, 맵리듀스에서는 YARN 기반, 아마존 EC 인스턴스에서는 직접 구현을 할 수 있다. 하둡 전문가라면 자바를 이용해 H2O를 연동할 수 있다. 또한, 파이썬, R, 스칼라를 지원하고, 이들 플랫폼의 라이브러리로 연동을 시킬 수 있다.
프로젝트 : H20
깃허브 : https://github.com/0xdata/h2o
Read more: http://www.itworld.co.kr/slideshow/90912?slide=6#stage_slide#csidxf020e61191c9840a9fad7ef1a9bb47e 
Copyright © LinkBack
클라우데라 오릭스(Cloudera Oryx)
하둡을 대상으로 한 또 다른 기계 학습 프로젝트인 오릭스(Oryx)는 클라우데라 하둡 배포판이다. 클라우데라는 스파크 프로젝트를 이용한 스트리밍 데이터 분석을 강조하는데, 오릭스는 그 덕분에 실시간 스트림 데이터에 배치할 수 있는 기계 학습 알고리즘을 구현할 수 있다. 이는 실시간 스팸 필터나 추천 엔진에 사용된다.
최근에는 오릭스2라는 새로운 버전이 개발되고 있다. 성능을 높이기 위해 스파크 및 Kafka를 사용하며, 해당 구성요소를 한층 느슨한 형태로 작성해 향후 검증을 할 수 있다.
프로젝트 : Cloudera Oryx
깃허브 : https://github.com/cloudera/oryx
Read more: http://www.itworld.co.kr/slideshow/90912?slide=7#stage_slide#csidx6f567f5dd99130fad7d12b6035236f2 
Copyright © LinkBack
고런(GoLearn)
구글의 고(Go)는 5년밖에 되지 않은 언어이다. 그러나 라이브러리가 풍부해짐에 따라 폭넓게 사용되기 시작하고 있다. 고(Go)를 대상으로 하는 일체형 기계 학습 라이브러리가 없어 개발된 것이 고런(GoLearn)이다. 이를 개발한 스테판 위트워스에 따르면 고런은 ‘간결한 맞춤화’에 목표를 두는데, SciPY 및 R의 패턴을 채택해 라이브러리에 직접 불러와 처리할 수 있다는 점에서 간단하다. 맞춤화는 특정 애플리케이션에서 MIT의 라이선스를 받은 오픈소스, 데이터 구조를 쉽게 확장할 수 있다는 점에 근간하고 있다.
한편, 위트웍스는 쇼군(Shogun) 라이브러리에도 포함된 Vowpal Wabbit 라이브러리용 고 래퍼(Go Wrapper)도 개발했다.
프로젝트 : GoLearn
깃허브 : https://github.com/sjwhitworth/golea
Read more: http://www.itworld.co.kr/slideshow/90912?slide=8#stage_slide#csidxd1c20b67e3a5f118f6c953680dbb935 
Copyright © LinkBack
Weka
뉴질랜드 와이카토 대학교(University of Waikato)가 개발한 Weka는 데이터 마이닝에 목적을 둔 자바 기계 학습 알고리즘을 집대성했다. 이 GNU GPLv3-라이선스 라이브러리에는 기능성을 확대할 수 있는 패키지 시스템과 공식, 비공식 패키지가 포함돼 있다. Weka에는 소프트웨어와 사용 기법을 설명한 책도 들어있다. 앞서 개념을 파악하고 싶은 사람들에게 도움이 되는 내용이다.
Weka는 하둡 사용자를 주 대상으로 하고 있지는 않지만, 최신 Weka 버전용 래퍼 덕분에 하둡에서도 이용할 수 있다. 스파크는 지원하지 않고, 맵리듀스만 지원한다. Clojure 사용자 또한 Clj-ml 라이브러리로 Weka를 이용할 수 있다.
프로젝트 : Weka
Read more: http://www.itworld.co.kr/slideshow/90912?slide=9#stage_slide#csidxd0f1095dcb2c2d1ad0a561ac8998f1b 
Copyright © LinkBack
CUDA-Convnet
현재 대다수는 GPU가 특정 기능 구현에서는 CPU보다 성능이 앞선다는 사실을 안다. 그렇지만 GPU 가속화 기능이라는 장점을 이용하도록 프로그래밍을 해야 애플리케이션이 해당 기능을 이점으로 활용할 수 있다. CUDA-Convnet는 신경망 애플리케이션을 대상으로 한 기계 학습 라이브러리다. C++에 기반을 두고 있으며, 엔비디아의 CUDA GPU 프로세싱 기술을 이용한다(CUDA 보드에는 Fermi가 있어야 한다). C++가 아닌 파이썬을 사용하고 있다면, 결과물인 신경망을 파이썬 객체로 저장하면 된다. 초기 버전은 더 이상 개발되지 않는데, CUDA-Convnet2 버전으로 다시 탄생했기 때문이다. 여러 GPU와 케플러 GPU의 지원을 받는 것이 특징이다. 유사한 프로젝트인 Vulpes는 F#로 개발됐으며, 통상적으로는 닷넷 프레임워크와 연동된다.
프로젝트 : CUDA-Convnet
Read more: http://www.itworld.co.kr/slideshow/90912?slide=10#stage_slide#csidx3ac03ba7d0e00349c03712281f9d249 
Copyright © LinkBack
ConvNetJS
ConvNetJS는 이름이 암시하듯, 자바스크립트 기반의 신경망 기계 학습 라이브러리를 제공하는데, 브라우저를 데이터 워크벤치로 사용하게끔 도와준다. Node.js를 이용하는 사람들을 위한 NPM 버전도 있다. 라이브러리는 자바스크립트의 비동기성을 적절히 활용할 수 있도록 설계됐다. 예를 들어, 학습이 완료되면, 실행 콜백을 내보낼 수 있다. 이 라이브러리에는 다양한 데모 예제도 포함돼 있다.
프로젝트 : ConvNetJS
깃허브 : https://github.com/karpathy/convnejs
Read more: http://www.itworld.co.kr/slideshow/90912?slide=11#stage_slide#csidx23fa05600b60e29a9eb8015dc4bc969 
Copyright © LinkBack
'Infomation' 카테고리의 다른 글
| 모두의 연구소 : 기술 블로그 (0) | 2016.04.05 |
|---|---|
| 딥러닝 공부 가이드 (HW / SW 준비편) (0) | 2016.04.05 |
| 쉽게 풀어쓴 딥러닝(Deep Learning)의 거의 모든 것 (2) | 2016.03.28 |
| 신경망을 이용한 경제(주식) 예측 코드 분석 (0) | 2016.03.27 |
| 머신 러닝 롱숏 모델 : 로봇이 주식을 고를 수 있을까(메리츠 금융 증권) (0) | 2016.03.27 |